





Réplication par streaming PostgreSQL : usages et topologies
PostgreSQL est un gestionnaire de base de données libre, disponible sous licence BSD. PostgreSQL est un des gestionnaires de base de données respectant le plus les standards SQL. De plus, ce qui nous intéresse dans ce billet, c’est que celui-ci est disponible avec de nombreuses options permettant de mettre en place facilement un cluster haute disponibilité, dont la réplication par streaming PostgreSQL.

Replication par streaming PostgreSQL
La réplication par streaming permet d’avoir plusieurs noeuds PostgreSQL, synchronisés en temps réel. À chaque modification sur le serveur maître, ladite modification va être répliquée grâce à l’envoi de fichiers WAL (fichiers de données internes à PostgreSQL) depuis le maître vers les esclaves.
Pour envoyer et recevoir les fichiers WAL, il existe deux processus : le « wal sender » et le « wal receiver ». Le »wal sender » sur le maître va se charger d’envoyer les fichiers WAL au processus appelé « wal receiver » qui va les recevoir et les appliquer.
Dans le cas de la réplication par streaming, l’avantage est que PostgreSQL n’a pas besoin d’attendre qu’un fichier WAL soit complet avant de l’envoyer, il enverra ceux-ci en mode « incremental », ce qui permet notamment d’avoir des données « récentes » plus rapidement sur les serveurs esclaves.
Réplication par streaming : prise de décision et usages
La réplication par streaming PostgreSQL : les points à prendre en compte
Lors de la mise en place d’une réplication par streaming, plusieurs points sont à prendre en compte :
- Combien de temps au maximum mon serveur esclave peut être arrêté sans devoir resynchroniser toutes les données depuis le début au rallumage ?
- Quelle procédure puis-je mettre en place pour promouvoir facilement un esclave en maître si un maître venait à tomber en panne ?
- Mes esclaves seront-ils « actifs » (j’execute des requètes en lecture seule dessus), ou « passifs » uniquement en cas de défaillance du maître ?
La réplication par streaming : les usages
Non seulement la solution de réplication par streaming PostgreSQL est idéale pour mettre en place de la haute disponibilité pour votre application, mais en plus, celle-ci vous permettra de partager la charge de travail PostgreSQL entre tous vos noeuds, réduisant ainsi la charge sur le serveur principal, grâce notamment à des outils comme HAProxy.
Il est très facile d’ajouter par la suite un ou plusieurs serveurs esclaves selon les nécessités sans avoir aucun impact au niveau du maître.
En mettant en place la réplication, il est aussi possible de conserver les fichiers de transactions (WAL) sur un disque, un serveur, ou un espace de stockage à part, pour pouvoir, en cas d’urgence, restaurer vos bases à une version antérieure ou à une date exacte choisie.

Différentes topologies de réplication
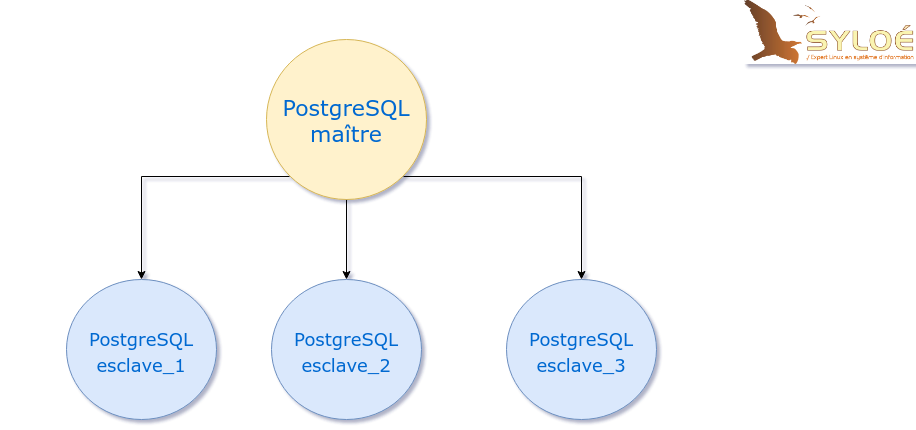
Réplication par streaming classique
Dans le cas de la réplication dite classique, le serveur maître va envoyer ses fichiers de transactions (WAL) à chaque esclave du cluster individuellement. Ceci augmente la charge du serveur maître et surtout son utilisation de bande passante. Si le serveur maître tombe, il faudra remplacer la source de réplication sur tous les serveurs esclaves.
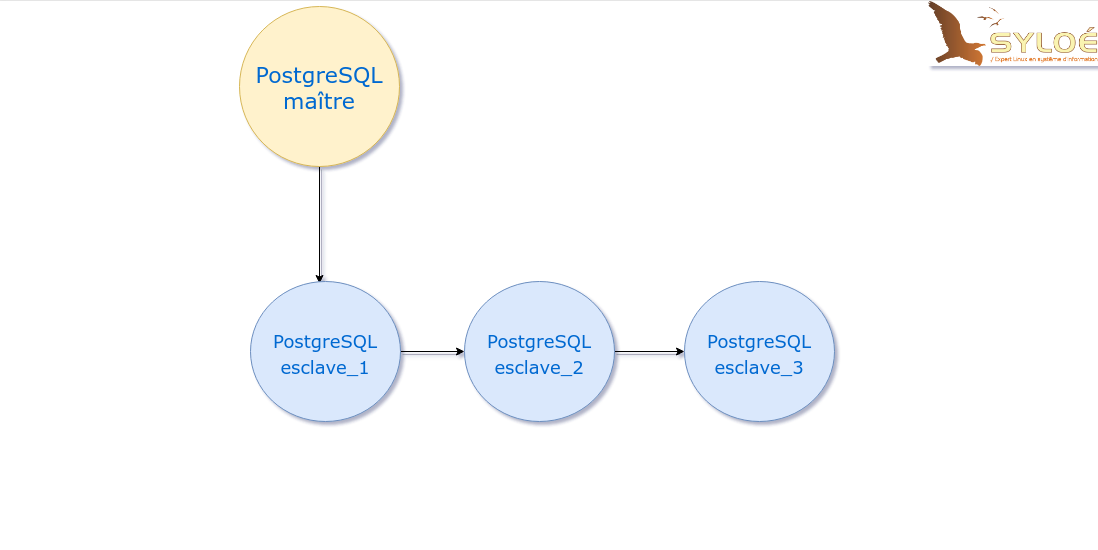
Réplication par streaming en cascade
Dans le cas de la réplication dite « en cascade », le serveur maître envoie ses fichiers de transactions (WAL) à un esclave, qui à son tour va envoyer ses fichiers à l’esclave suivant etc. Si un esclave tombe en panne, il suffira de remplacer une seule fois la source de réplication par un autre.
Monitoring de la réplication
Grâce à Zabbix, nous pouvons facilement superviser vos instances PostgreSQL, détecter des anomalies éventuelles, grapher le délai de réplication, dit « lag », détecter des changements de topologie, des erreurs dans les journaux etc.
Contactez Syloé, Experts Linux
Vous souhaitez mettre en place un cluster PostgreSQL haute-disponibilité ? N’hésitez pas à contacter un Expert Syloé. Syloé peut vous apporter son expertise personnalisée sur tous ces points et d’autres.
Comparaison entre les réplications PostgreSQL et MariaDB (MySQL) - Blog Syloé
[…] réplication en continu (streaming) de PostgreSQL ou la réplication par archive réplique toutes les bases de données de […]